import numpy as np # linear algebraimport pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)import matplotlib.pyplot as pltimport osfor dirname, _, filenames in os.walk('/kaggle/input'):for filename in filenames:print(os.path.join(dirname, filename))
Here, we have loaded the data and set Furan as the label. At first, we have used 25 percent of the dataset A as the test set to come up with a good model, and then use this model to test in the dataset B.
ds_A = pd.read_csv("/kaggle/input/transformer/DatasetA.csv")ds_B = pd.read_csv("/kaggle/input/transformer/DatasetB.csv")# Splitting train and testfrom sklearn.model_selection import train_test_splittrain_set_A, test_set_A = train_test_split(ds_A, test_size =0.25, random_state =11)# Setting the labelsy_train_A = train_set_A['Furan']y_test_A = test_set_A['Furan']# Dropping the Furan and Health Index columnsX_train_A = train_set_A.drop(["Furan", "HI"], axis =1)X_test_A = test_set_A.drop(["Furan", "HI"], axis =1)# For DatasetBy_B = ds_B['Furan']X_B = ds_B.drop(["Furan", "HI"], axis =1)# The code below is for the second case, where we train the data for the whole# Dataset A and test it on Dataset By_A = ds_A['Furan']X_A = ds_A.drop(["Furan", "HI"], axis =1)
/opt/conda/lib/python3.10/site-packages/scipy/__init__.py:146: UserWarning: A NumPy version >=1.16.5 and <1.23.0 is required for this version of SciPy (detected version 1.23.5
warnings.warn(f"A NumPy version >={np_minversion} and <{np_maxversion}"
The code below, drops the columns that we don’t need, and only keeps the common features between dataset A and B.
First case: Training using 75% of the data and testing on the remaining 25%
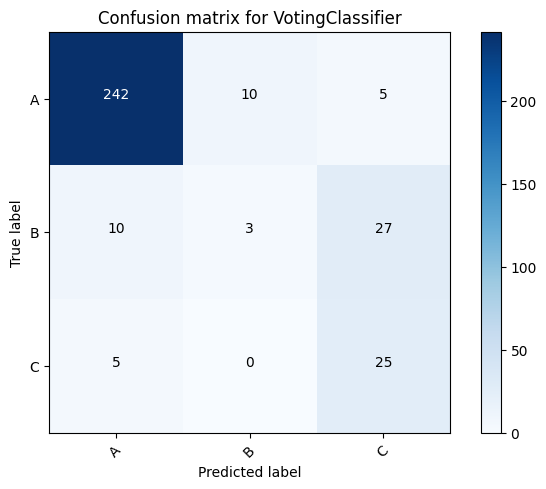
We have experimented a combination of different models in the ensemble. Although the results were quite similar, we found that a combination of KNN, XGB and logistic regression works best. In the code below we have created a voting classifier consist of these models.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
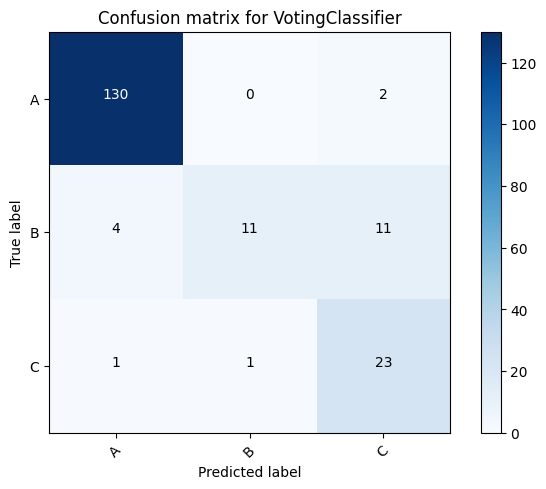
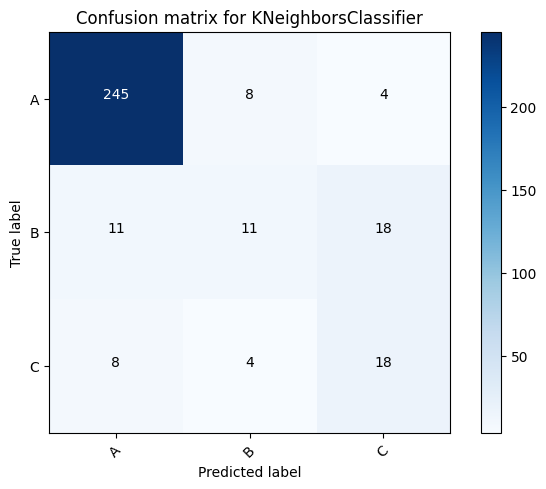
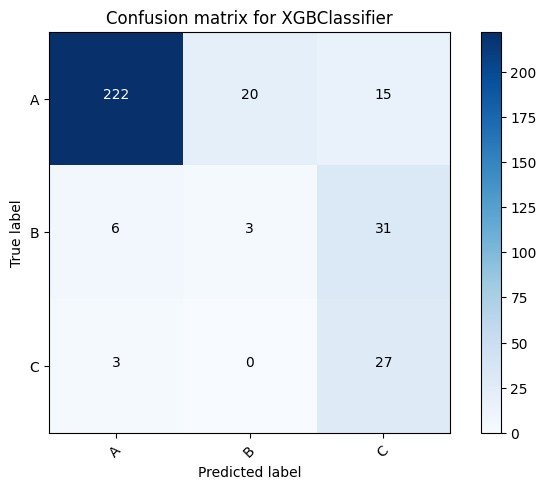
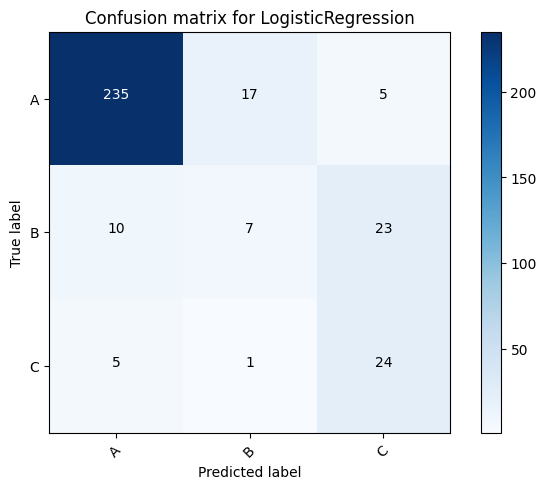
Here is a comparison of different models and the voting classifier.
from sklearn.metrics import accuracy_scorefor clf in (mlp_clf, svm_clf, #ada_clf, knn_clf, xgb_clf, #nb_clf, lr_clf, voting_clf): clf.fit(X_train_A, y_train_A) y_pred_A = clf.predict(X_test_A) y_pred_B = clf.predict(X_B)print(clf.__class__.__name__+" for dataset A:", accuracy_score(y_test_A, y_pred_A))print(clf.__class__.__name__+" for dataset B:", accuracy_score(y_B, y_pred_B))
/opt/conda/lib/python3.10/site-packages/sklearn/neural_network/_multilayer_perceptron.py:686: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (1000) reached and the optimization hasn't converged yet.
warnings.warn(
MLPClassifier for dataset A: 0.8688524590163934
MLPClassifier for dataset B: 0.7828746177370031
SVC for dataset A: 0.8797814207650273
SVC for dataset B: 0.8103975535168195
KNeighborsClassifier for dataset A: 0.8360655737704918
KNeighborsClassifier for dataset B: 0.8042813455657493
XGBClassifier for dataset A: 0.8961748633879781
XGBClassifier for dataset B: 0.764525993883792
LogisticRegression for dataset A: 0.8633879781420765
LogisticRegression for dataset B: 0.7951070336391437
VotingClassifier for dataset A: 0.8961748633879781
VotingClassifier for dataset B: 0.8195718654434251
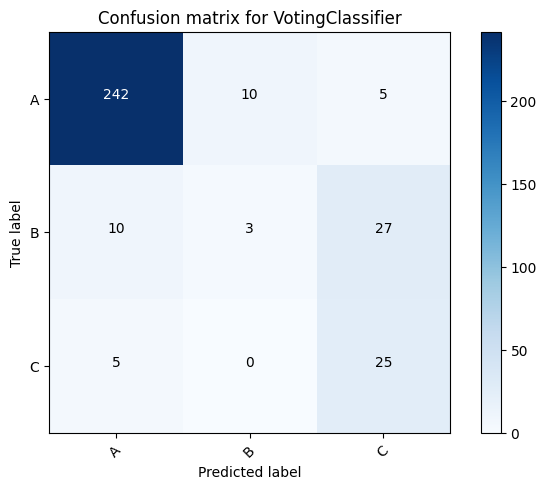
Second case: Training using all of the data from Dataset A
So far we have used 75% of Dataset A to train the data and 25% to test it. Here, we used all of the data from Dataset A to train, and then test it on Dataset B.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
from sklearn.metrics import accuracy_scorefor clf in (#mlp_clf, svm_clf, #ada_clf, knn_clf, xgb_clf, lr_clf, #nb_clf, voting_clf): clf.fit(X_A, y_A) y_pred_B = clf.predict(X_B)print(clf.__class__.__name__+" for dataset B:", accuracy_score(y_B, y_pred_B))
KNeighborsClassifier for dataset B: 0.8379204892966361
XGBClassifier for dataset B: 0.7706422018348624
LogisticRegression for dataset B: 0.8134556574923547
VotingClassifier for dataset B: 0.8256880733944955
The code below is a function to visualize the confusion matrix